

Big Data – Big Overload
[wp_charts title=“mydough“ type=“doughnut“ align=“alignleft“ width=100% margin=“2px 2px“ data=“30,10,55,25,15,8″ colors=“69D2E7,#E0E4CC,#F38630,#96CE7F,#CEBC17,#CE4264″]
[wp_charts title=“radarchart“ type=“radar“ align=“alignleft“ width=100% margin=“2px 2px“ datasets=“20,22,40,25,55 next 15,20,30,40,35″ labels=“one,two,three,four,five“ colors=“#CEBC17,#CE4264″]
[wp_charts title=“mypolar“ type=“polarArea“ align=“alignleft“ width=100% margin=“2px 2px“ data=“40,32,5,25,50,45″ labels=“one,two,three,four,five,six“]
Fortunately, we humans are intensely visual creatures. Few of us can detect patterns among rows of numbers, but even young children can interpret bar charts, extracting meaning from those numbers’ visual representations. For that reason, data visualization is a powerful exercise. Visualizing data is the fastest way to communicate it to others.
Das habe in Scott Murray’s Buch „Interactive Data Visualization for the Web“ gelesen. „… the fastest way to communicate“ (Hier gibt’s das Buch als Online Version). „Klingt gut“ dachte ich und begann mich weiter mit dem Thema zu beschäftigen.
Die „Secrets & Hints“ für die inhaltliche und praktische Adaptierung des Themas lagen dann aber leider nicht gerade zum Auflesen auf der Strasse. Beim Googeln und diverser Lektüre flattern mir zwar zahlreiche hervorragende aber noch zahlreicher schlecht umgesetzte Visualisierungen, Infographics, Frameworks, Tools und Schlagworte um Augen und Ohren, aber den ultimativen „Visualisierungs Guide“ suche ich vergeblich …
Konzeptenwicklung für eine Visualisierung mittels „Sketch&Draw“.
Was ist die richtige Strategie für „Visualize Big Data“? Was sind die Basics, wo finden sich leistungsstarke Werkzeuge & Frameworks und wie lassen sich Data-Visualisierungen praktisch in den Unterricht einbringen? Das frage ich mich im Rahmen meiner Tätigkeit immer wieder. Und wie so häufig, folgt bei der Annährung an ein neues „Hype-Thema“ schnell der frustrierende Internet-Overload an divergierenden und unausgegornen Informationen. Aber ich will es genauer wissen und mich nicht irritieren lassen. In der Folge habe ich dann mein „sommerliches Ferienziel“ an einen Kurs der „HU University of Applied Sciences Utrecht Communications and Journalism (HU)“ verlegt: „Storytelling with Data Visusalization“. Nun also ein „Crash Kurs für Data-Visualizing mit entsprechender Data-Shower“. Mit gemischten Erwartungen reise ich nach Utrecht. Vor der Abreise hat mir mein Mann noch einen Artikel-Ausriss an den Koffer geklebt. Auf dem Zettel stand:
„Respect Human Visual Limitations“.
Zwei Wochen lang sollten wir uns da in einer bunt zusammen gewürfelten Studiengruppe aus zwei Irrländern, einem Spanier, einer Holländerin, einem Schweizer und einer Schweizerin, einer Russin und einer Polin sowie mit der holländischen Kursleitung und Gastdozentinnen auseinander setzen, wie man am besten aus „Daten“ Bilder und Geschichten visualisieren kann, die mehr aussagen, als reine Zahlen- oder Datenreihen. Alle Teilnehmerinnen und Teilnehmer sollten während des Camps ein selber erarbeitetes, konkretes Beispiel angehen und umsetzen. Ein umfangreiches Programm steht bevor (hier geht’s zum Kursprogramm).
„Datenjournalismus & Visual Storytelling“ – was ist das?
Ein erster Einstieg liefert ein Artikel aus dem Guardian Data Blog: „Our 10 point guide to data journalism and how it’s changing“. In diesem Beitrag wird anschaulich erklärt, was Datenjournalismus ist. Ich überlese aber zuerst, dass 80% der Arbeit in der Bereitstellung der Daten liegt. Was das genau bedeutet, würde ich in den nächsten Tagen lernen müssen. Interessiert schauen wir zusammen zahllose Webseiten mit interessanten Analytics, Visualisierungen sowie vielversprechende neue Tools an und versuchen die gezeigten Konzepte zu verstehen. Wir haben uns vorgenommen, dass wir alle während des Kurses ein eigenes „Visual-Data“-Projekt erarbeiten. Alle suchen entsprechend gespannt nach adaptierbaren Ansätzen und praktischen Hints. Schnell merken wir, dass dabei der visuelle Overload und die damit verbundenen Optionen gigantisch sind und ein „roter Faden“ für langfristige Umsetzungsstrukturen nur schwer auszumachen ist.

Wieviele Infografiken und Big Data Charts verkrafte ich an einem Tag?
Diese Frage habe ich mir während der Kurszeit häufig gestellt. Wir leben jetzt im Zeitalter der Bilder. Lesen gehört für viele nicht mehr zu den alltäglichen Dingen. Viel lieber wollen wir schnell wahrnehmen, skimmen, und erst wenn wir uns die Übersicht verschafft haben, lassen wir uns in ein Thema ein. Das heisst wohl, dass lange Textpassagen“out“, Bilder und visuelle Elemente hingegen „in“ oder Trend sind. Die daraus entstehende Flut durch Visualisierung ist gewaltig.
Dass Infografiken und Visual Data Maps weit mehr sind, als Umsetzungen von Daten in bunte interaktive Grafiken, zeigt sich schnell bei den ersten konkreten Umsetzungsversuchen. Viele der angegangenen Visualisierungen kommen auf den ersten Blick „good looking“ daher, erzählen oder erschliessen bei näherer Betrachtung aber dann doch keine Geschichte. Sie täuschen faktenreiche Inhalte oft nur vor oder werden von den Leistungsmerkmalen der eingesetzten Tools limitiert oder häufig mit wiederkehrenden Symbolen unattraktiv und zum verwechseln ähnlich normiert. Nur Visualisierungen mit strukturierten und zusammenfassenden Daten erzählen eine Geschichte im Kontext ihrer Thematik, die sich dann auch wirklich als “ fastest way to communicate“ auf der X/Y-Achse erweisen.
Nach hunderten von durchgeklickten „Best Parctice Links“ bin ich so „Grafik-satt“ und „Tool-müde“ wie noch nie zuvor. Auch meine Studienkolleginnen und -kollegen zeigen nach den ersten Tagen ähnliche Symptome. Erste Ernüchterung macht sich breit. „Welcome Back“ auf dem Boden des Machbaren. Zeitgutscheine werden keine verteilt … Das Knowledge-Management und die nach oben offenen Optionen fordern ihren Tribut: Der Ruf „reduce to the max“ geht durch die Reihen.
Viele „Data-Visualisierungen“ nerven und verwirren unsere Wahrnehmung mit unklarem oder gepimptem Sachverhalt. Weder erklären noch vereinfachen sie das verwendete Datenmaterial. Da befindet sich zum Beispiel keine Legende direkt neben dem Chart und ich muss mir die Farbe „hellorange“ aus einer mühsam aus einer langen Liste klauben, wenn ich sie dann überhaupt zuordnen kann. Sieht zwar gut aus, ist aber unübersichtlich. Und schon ist es vorbei mit der Aufmerksamkeit. Es ist offenbar nicht so einfach, klare typografische Regeln und bekannte Gestaltungstheorien 1:1 auch im Bereich von „Visualize Big Data“ einzuhalten und umzusetzen. Auch die referierenden Experten skizzieren Umsetzungsregeln nur in Ansätzen und die gezeigten Tools liefern die vollständige grafisch korrekte Umsetzung häufig nicht einfach „automatisch“, wie das heute gerne kolportiert wird.
In einem HBR-Blog stosse ich auf einen interessanten Beitrag: „Five Roles You Need on Your Big Data Team“
1. Data Hygienist
2. Data Explorers
3. Business solution Architects
4. Data Scientist
Das bringt es auf den Punkt. Diese Rollen spiele ich nun in den folgenden Tagen bei meiner konkreten Projektarbeit durch.
Umsetzung mit „tableau“
[youtube id=“yJI3dV2FWwU“]
(Video tableausoftware youtube.com)
Ich entscheide mich für den Einsatz des Visualierungs-Tool ‚tableau‘. „tableau Data visualization allows anyone to organize and present information intuitively. This is becoming more vital as data proliferates in every field from bar codes in retail stores to player behavior in online games. All of this data is meaningless without a way to organize and present important findings within it.“ heisst es in der Produkt-Präsentation vielversprechend. In der Folge absolviere ich dann aber mehrere „Try & Error“-Loops, um zur eigentlichen „Kür“ für die Umsetzungsstrategie meines eigenen Daten-Projekt „CH Städteentwicklung“ zu gelangen. Die Werbeaussage: „Visual analytics for everyone – Easy to use, easy to love“ relativiert sich bei der konkreten Arbeit deutlich …
Bei der Suche nach der Umsetzungsstrategie mit diesem Werkzeug verdeutlichen sich mir nun aber relevante Umsetzungspunkte:
Wo sind adaptierbare Datenquellen (Open Data)? Hife, wir brauchen mehr Datenscouts.
Wo finde ich die guten Daten? Die Regierungsadministrationen haben sich verpflichtet, dass sie ihre Daten offen legen. Doch die Ergebnisse aus ihrer Verpflichtung sind häufig schwer auszumachen. Manchmal verstecken sich die Daten in Texten und man muss sie in Kleinarbeit herausfiltern. Manchmal werden sie in unendlich langen PDFs publiziert. Glück hat man, wenn man direkt eine Excel-Datei oder ein .csv-File findet. Ich nehme mir vor zu Hause mein eigenes Repository solcher Quellen zu erstellen.
Hier die drei Links, die ich dann für mein Projektbeispiel verwendet habe:
1. Statistische Daten bei der Stadt Zürich
2. Bundesamt für Statistik
3. Opendata
Wie lassen sich Daten schnell in die richtige Struktur konvertieren, so dass sie maschinenlesbar sind?
Wo ist der effiziente Datencleaner und was sind die besten Formate?
.XLS- und .CSV-Formate, PDF in Excel „umfüllen“, amerikanische Datenformate konvertieren, automatisch und manuell Geodaten ergänzen und den richtigen Ortschaften zuordnen. Eigentlich alles nur halb so wild, aber es braucht dann doch einige Zeit, bis die Daten sauber und verwertbar strukturiert sind. Und so komme ich auch zu einem Exkurs um den Dreh- und Angelpunkt in Pivot-Tabellen zu verstehen, damit sich die Daten-Aggregierung in den Datenfeldern die Ausgangsdaten in verdichteter, zusammengefasster Form darstellen lassen.
Wie wähle ich eigentlich die richtige Präsentationsform für die Daten?
Wo gibt’s einen Guide der zeigt, welche Datenart sich mit welcher Darstellung am umsetzen lässt?
Die dritte Frage ist eine zentrale Angelegenheit. Ich kämpfe mich durch die Literatur und zurück bleibt die Fragestellung, ob denn wirklich bisher noch keiner eine Visualisierung fürs Datenvisualisieren gemacht hat?
Der amerikanische „Information Architect“ und Graphic Designer Richard Saul Wurman teilt Informationsorganisation in 5 Arten auf:
- Location
- Alphabetical
- Time
- Categorical
- Hierarchical
Ok, alphabetisch und zeitlich sind Subkategorien von hierarchisch, somit sind es also drei Hauptkategorien. Jetzt beginnt die eigentliche Arbeit und es gilt, möglichst viel Erfahrung zu sammeln. Wann nehme ich eine Tortengrafik? – Aha, wenn ich die Teile mit dem Ganzen vergleichen will. Wann nehme ich eine Balkengrafik? Aha, wenn ich Grössen über verschiedene Kategorien vergleichen möchte, wobei gilt, dass die wichtigste Grösse immer unten auf dem Balken zu liegen kommt. … Zwei Wochen lang suche ich nach Strukturen und ich nehme mir vor, dass ich zu Hause einmal versuchen werde, eine Visualisierung zu machen, welche Daten wie am besten zu visualisieren sind.
Wie gestalte ich die Daten und wie fasse ich sie zusammen?
Welche Analytic hilft hier?
Hier geht’s nicht nur um die Wahl des richtigen Tools, sondern auch des richtigen Layouts der Exceltabelle als Data-Source. Was muss ich vorher berechnen und welche Daten eigenen sich für die visuelle Darstellung? Der gestalterische Teil ist nur an einem kleinen, aber doch auch wichtigen Ort. Die gute alte Gestalttheorie und typografische Kenntnisse helfen hier etwas weiter.
Wie „verkaufe“ ich die Visualisierungen?
Wo ist eigentlich unser „Campaing Expert“?
Mein erstes „Big Data“-Projekt
Korrekt müsste es wohl „Small Data“-Projket heissen. Aber für den Einstieg war’s genau richtig. Ich habe mir im Rahmen des Kurses eine Visualisierung zur „Städteentwicklung in der Schweiz“ als Problemstellung abgesteckt. Der Städteverband der Schweiz hat eine Publikation zu „Sicherheit als Standortfaktor für Schweizer Städte – heute und 2025″ mit entsprechenden Resultaten erstellt, die ich als Ausgangssituation genommen habe. Als Daten-Grundlage verwende ich dabei die frei zugänglichen Datenreihen zur Bevölkerungsentwicklung (Statistik der Schweizer Städte 2013, Statistiques des villes suisses 2013).
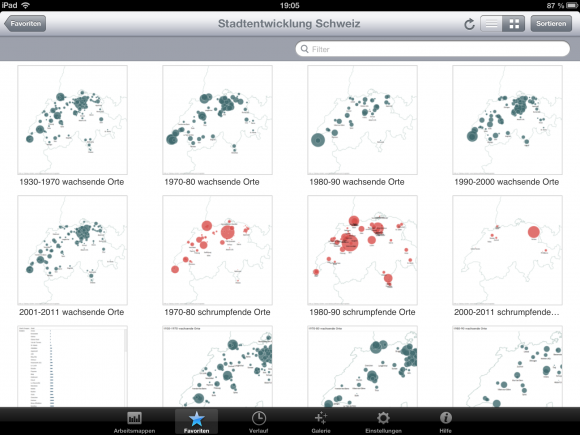
Die erste Karte zeigt die Geschichte der Zunahme der Einwohnerzahlen der 160 grossen oder grösseren Orte zwischen 1930 und 1970. Durch die Umsetzung der Daten aus einem Excel auf eine Karte wird auf einen Blick sichtbar, dass Zürich am meisten gewachsen ist, aber auch, dass die vielen Orte entlang der beiden Zürichseeufer stark gewachsen sind,
In den nackten Daten sind solche geografischen Trends nicht direkt ersichtlich, da zum Beispiel Adliswil und Amriswil zwar nebeneinander in der Tabelle stehen, aber in dieser Anordnung kein Muster erkennbar ist. Die geografische Anordnung der Entwicklungsschritte über mehrere Jahrzehnt zeigt deutlich, wie der Trend der Bevölkerungsveränderung ist. während der Bevölkerungszuwachs in den Orten in Graubünden stagniert oder sinkt.[highlight color=“orange“] Meine realisierten Data-Maps finden Sie hier: [/highlight] Weiter …
Fazit:
In 14 Tagen haben wir uns in der „Summer School“ der Universität Utrecht dem Thema „Visual Storytelling with Data“ genähert, sind durch Datenberge gescrawlt und haben dabei zahlreiche Tools und Frameworks angestossen, die nun zu vertiefen sind.
Ich danke allen Beteiligten herzlich für die interessanten Gespräche und den damit verbundenen Input. Und natürlich danke ich auch für unsere gemeinsamen „Radel-Touren“ durch den schönen Wald im niederländischen Woudschoten. Das Radfahren hat uns jeweils am Abend vom Overload des Tages befreit.
Eine wesentliche Erkenntnis habe ich an diesem Kurs gewonnen: „Du darfst dich nicht verunsichern lassen, weil sich „Big Data“ ja schon so „big“ anhört. Der Open Data Trend geht weiter. Natürlich gilt es die Komplexität von aussagekräftigen Visualisierungen und den Einsatz geeigneter Tools nicht zu unterschätzen. Aber du brauchst vor allem eigene Ideen und eine eigene Strategie, um eigene „Big Data Geschichten“ visuell zu erzählen.
Natürlich ist „Big Data Visualizing“ stark „Technik-driven“ und es gibt reihenweise verschiedene Ansätze. Ich glaube aber feststellen zu können, dass Javascript als zentrale Entwicklungssprache die Nase vorne hat und durch die vielen verfügbaren Frameworks eine nachhaltige Entwicklungsschiene für „Data Visualizing“ darstellt.
Allen voran sehe ich das D3-Projekt: http://d3js.org/ das eine transparente Grundlage für eigene Projekte bildet.
Ein D-3 Visual Index, Gallery findet sich auf „Github“: https://github.com/mbostock/d3/wiki/Gallery und die entsprechende API-Reference hier: https://github.com/mbostock/d3/wiki/API-Reference, ebnso ein umfangreiches Tutorial: https://github.com/mbostock/d3/wiki/Tutorials
Wer sich einen Überblick über die relevanten Themenfelder für die D3-Visualisierung verschaffen will, dem empfehle ich eine Workshop-Präsentation von D3-Grossmeister Mike Bostock @mbostock – die Slides finden sich hier: http://bost.ocks.org/mike/d3/workshop/#0. Die Präsentation ist ein „Short-Guide“, welche spezifischen Web-Standards für Visualisierungen grundlegend sind.
Weiterführende Kindle eBooks:
Scott Murray, Data visualization for the Web – An Introduction to Designing With D3
Big Data Glossary – A Guide to the New Generation of Data Tools
Beautiful Visualization – Looking at Data Through the Eyes of Experts
Visualize this – The FlowingData Guid to Design, Visualization an Statistics
Lesen Sie auch meinen Beitrag: Das virtuelle gibt es so nicht mehr