
Radmila hat heute wiederum einige Tipps, um nützliche Skripts von Vorlesungen herunterzuladen.

Studenten präsentieren in Lev Manovichs Klasse (analysis and visualization of large media data sets) auf einem “ HiperSpace scalable visualization system“.
Oder auch auf aaaaarg.org und avaxsearch.com kann man wertvolle Lektüre bekommen
Somit können wir uns mit den eigentlichen Fragestellungen auseinandersetzen:
- Data is not new
- What is new?
- Ubiquity of data
- Amount of data/the speed at witch it has been generating
- real-time data
- Computer processing of data in real-time
- Dynamic interactive visualizations
- Algorithms – how reliable (automatized data analysis)
- Statistical analysis: small data sets versus big data analysis
Manuel Lima
Auf Infoaesthetics gibt es eine grosse Menge an visuell aufbereiteten Daten zu finden. Das visuelle Gefühl lernt man am besten, wenn man die Dinge genauer anschaut. Wie sind sie gemacht? Und warum sind sie so gemacht? Die Frage, warum welche Datensets genommen wurden, das ist immer die zentrale Frage.
Reverse Engineering ist angesagt. So sammeln wir Ideen und Motivation, uns selbst an die Daten zu wagen.
Zitat Radmila: Big-data – large and complex data sets cannot be handled with traditional data management tools.
Wie sind die Daten eigentlich geregelt?
Open Data Law
hier kommen die Links zu freedom of information act
Die Regelung in den US
http://www.justice.gov/oip/foia_updates/Vol_XVII_4/page2.htm
In der Schweiz ist das geregelt mit dem Bundesgesetz über die Öffentlichkeit der Verwaltung.
Tableau
hier fehlt der Kontext … ist irgendwie verloren gegengen im Vortrag http://www.tableausoftware.com/de-de
This is what builds Visualisation
Spatial substrate
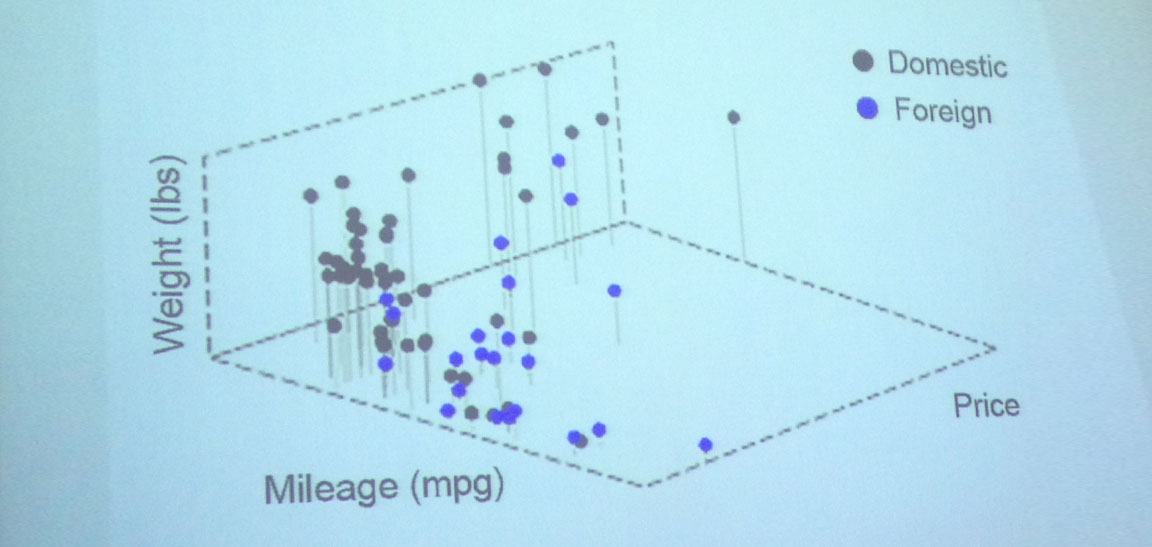
Die Verteilung der Dinge im Raum. Hier ist mit drei Dimensionen gearbeitet.
Graphical Elements
Linie, Punkt, Fläche
Graphical Properties
Size, Orientation, …
Color Texture and Shape
Human Interaction
Entweder du kannst etwas interagieren wie hier http://moritz.stefaner.eu/projects/map%20your%20moves/
oder hier http://www.nytimes.com/interactive/2009/07/31/business/20080801-metrics-graphic.html?_r=0 und http://www.nytimes.com/interactive/2012/09/06/us/politics/convention-word-counts.html
Der Baynamen-Wizzard sucht die Häufigkeit von Vornamen in den US heraus http://www.babynamewizard.com/voyager#prefix=carlotta&ms=false&exact=false
Google hat es gekauft
Gapminder ist sehr verbreitet, wie immer, weil es open source ist http://www.gapminder.org/
Hier ein Video http://www.gapminder.org/videos/hans-rosling-ted-talk-2007-seemingly-impossible-is-possible/
Stephen Few Perceptualedge.com
Literaturtipp: 
Variablen in der Infografik
Wenn wir die Produktivität von drei Autofirmen messen, dann ist das „the case“, also das was wir messen wollen.
Der Umsatz ist die erste Variable, die Zeit kann dann eine zweite Variable sein.
Es gibt die Grundregel, dass wir das was wir gemessen haben oder vergleichen wollen auf die x-Achse stellen, also unten auf der Horizontalen liegt.
Ein Beispiel:
Ich will meine Blumen im Garten vergleichen. Ich messe deren Höhe (1. value), die Anzahl (2. Value) und die Farbe (3. Value). Als vierten Wert könnte man noch den zeitlichen Ablauf (4. Value) anfügen. Wie sieht die Grafik aus?
Der Case, also die Blumen stehen auf der x-Achse.
Die erste Variable geht auf die y-Achse.
Die zweite Variable zeigt sich in der Breite der Säule (bei der Balkengrafik)
Ok, die dritte Variable geht auf die grafische Eigenschaft.
Quora
University of Missoury
Info chimps
The data and Story Library (DASL)
Global Health facts
Gapminder
OECD
Census
DAtagov
The World Bank
http://data.un.org
Aus Visualize this
www.freebase.com
www.infochimps.org
http://aggdata.com
http://aws.amazon.com/publicdatasets
http://wikipedia.org
Geografische Daten
www.census.gov/geo/www/tiger
www.openstreetmap.org
www.geocommons.com
www.flickr.com/services/api
World
www.globalhealthfacts.org
http://data.un.org
www.who.int/research/en/
http://stats.oecd.org
http://data.worldbank.org
Politik
www.opensecrets.org
www.followthemoney.
Searchtip: „site: .gov“ filetype: .xls
_____________________________
Datenputzen kann man hier
Scraper wiki https://scraperwiki.com/
Knime http://www.knime.org/
Github https://github.com/OpenRefine
outwit